Základní výstupy a editace šablon
Obrázek 1: Editace šablony výstupu
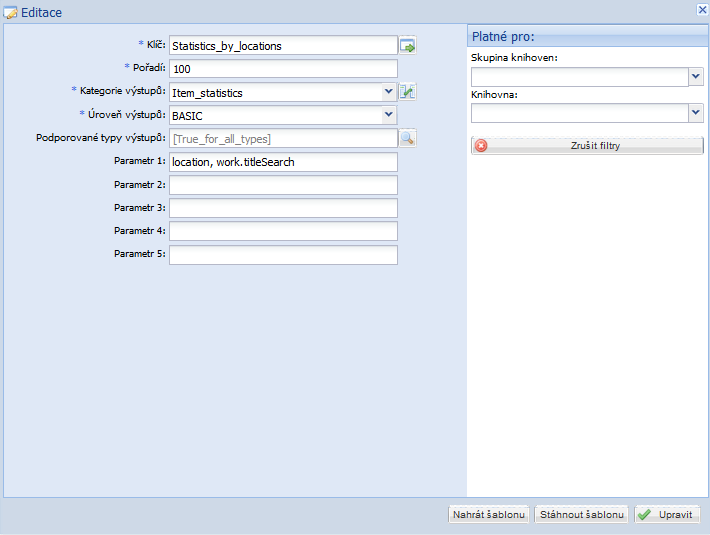
Editace šablony výstupu
Klíč: název šablony pro který je potřeba ještě vytvořit překlad buď tlačítkem vedle nebo vytvořením překladu v Systém -> Překlady -> Vytvořit
Pořadí: číslo, které určuje pořadí sestavy v seznamu v kategorii výstupu
Kategorie výstupu: určuje místo, kde se má sestava objevit, např.: Item_basic_output je okno Základní přehled svazků
Úroveň výstupu: pro základní šablony se vždy vybere BASIC
Podporované typy výstupu: (nepovinné) vyberete pokud je potřeba omezit sestavu na určitý formát výstupu, např.: pouze pro excel či pdf
Parametry: viz níže v odstavci Parametr 1
Platné pro: nastavení skupiny uživatelů, kteří uvidí a budou moci použít šablonu
Nahrát šablonu: slouží pro nahrání souboru/šablony z IReport ve formátu .jrxml
Stáhnout šablonu: umožňuje stáhnutí souboru/šablony, která je již v Tritiu uložena pro tuto sestavu
Upravit: uloží změny provedené v nastavení šablony výstupu
Řazení
Řazení je důležité nejen pro vizuální vzhled výstupu, ale také pokud je v šabloně použito seskupování. Pokud by se v šabloně data seskupovala např.: podle lokace, a data na vstupu by nebyla seřazena podle lokace, tak by na výsledném výstupu vzniklo více stejných skupin/lokací - což je špatně.
Základní výstupy mají dva způsoby řazení:
- řazení podle filtru (řádky budou ve vygenerovaném výstupu seřazeny/seskupeny, tak jak byly na vstupu)
- řazení podle Parametr 1 (Parametr 1 umožňuje nastavit, jak budou data vždy seřazena/seskupena nezávisle na vstupním seřazení dat)
- řazení podle proměnné v iReport
Parametr 1
Na obrázku 1 je vidět, že nastavení šablony pro výstup umožňuje vyplnění Parametru 1, ostatní parametry nejsou momentálně pro základní výstupy využity. Zde je možné vyplnit až dvě proměnné podle, kterých mají být data automaticky seřazena pro šablonu. Není tedy potřeba, aby uživatel řadil, kvůli seskopování dat ve výstupu, před generováním výstupu.
Na obrázku 1 je vidět, že proměnné se oddělují čárkou, je možné použít až dvě proměnné, kdy se data budou řadit nejdříve podle první proměnné a sekundárně se doseřadí podle druhé. Např.: pokud bude vyplněno location, work.titleSearch, tak budou řádky ve výstupu nejdříve seřazeny podle lokace a následně podle názvu.
Proměnné
Názvy proměnných odpovídají názvům proměnných v Tritiu, jsou to tedy většinou anglické ekvivalenty pro hodnoty, které uchovávají, např.: lokace - location, tematická skupina - thematicGroup. Pokud se hodnota váže k dílu, né tedy k svazku - musí se přidat work., např.: název díla - work.titleSearch.
Výčet nejčastěji používaných proměnných:
- location - lokace svazku
- thematicGroup - tematická skupina svazku
- acquisitionType - způsob nabytí svazku
- work.titleSearch - název díla
- work.authorSearch - autor díla
Parametr 2
- Výstupy mohou být parametrizované, tzn. čtenář může omezit data, která se mají načítat.
- Např. načtení výpůjček konkrétního čtenáře za časové období.
- Tyto parametry je nutné v šabloně definovat
- Přidání parametru v iReport:
- Pravým na Parameters -> Add Parameter
- Vhodně parametr pojmenovat a nastavit mu datový typ
Definice v šabloně
- Parametr je poté možno používat v šabloně pomocí zápisu $P{název_parametru}
Je možno použít parametr přímo v SQL pro načítání
Parametr v SQL
<parameter name="l1" class="java.lang.Long"/>
<queryString language="SQL">
<![CDATA[
SELECT [name] AS work_type_name
FROM [work_type]
WHERE [id] = $P{l1}
]]>
</queryString>
<field name="work_type_name" class="java.lang.String"/>
- Tímto způsobem je ovšem možno vložit parametr pouze bez nějakých dalších úprav
- Funguje pro řetězce, čísla
- Nefunguje pro datum a pokročilé struktury Tritia
- Pokud je parametr potřeba nějakým způsobem zpracovat, tak toto není možné v části s SQL (omezení JasperReports).
- Je nutné si vytvořit nový parametr, nastavit mu požadovanou hodnotu a teprve pak ho použít v šabloně.
- K takto vytvořenému parametru je nutno přistupovat přes $P!{název_parametru} (vykřičník navíc).
- Pro vytvoření hodnoty parametru se dá použít skládání hodnot jako v Javě.
Příklad:
Parametry v SQL - pokročilé
<parameter name="d1" class="java.util.Date"/>
<parameter name="d1_sql_condition" class="java.lang.String">
<defaultValueExpression><![CDATA["[work_type].[date_created] > '" + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format($P{d1}) + "'"]]></defaultValueExpression>
</parameter>
<queryString language="SQL">
<![CDATA[
SELECT [name] AS work_type_name
FROM [work_type]
WHERE $P!{d1_sql_condition}
]]>
</queryString>
<field name="work_type_name" class="java.lang.String"/>
- Pro datum 1.2.2015 10:00:00 bude v parametru d1_sql_condition nastavena hodnota "[work_type].[date_created] > '2015-02-01 10:00:00' ", což odpovídá SQL zápisu
Povinné a nepovinné parametry
- Pokud je parametr povinný, není potřeba ho ošetřovat.
- Nepovinný parametr může do šablony přijít jako NULL - je potřeba zajistit vytvoření validního SQL.
- K tomu se používá předzpracování parametru, viz výše.
- Využití ternárního operátoru
- Když je parametr různý od null, použij hodnotu A, jinak hodnotu B
- Podmínka 1=1 - neomezuje výsledky.
Příklad:
Nepovinný parametr
<parametername="d1"class="java.util.Date"/>
<parametername="d1_sql_condition"class="java.lang.String">
<defaultValueExpression><![CDATA[$P{d1} == null ? "1=1" : ("[work].[date_created] > '" + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format($P{d1}) + "'"]]></defaultValueExpression>
</parameter>
<queryStringlanguage="SQL">
<![CDATA[
SELECT [name] AS work_type_name
FROM [work_type]
WHERE $P!{d1_sql_condition}
]]>
</queryString>
<fieldname="work_type_name"class="java.lang.String"/>
- Pokud je parametr NULL, použije se podmínka 1=1 (načtou se všechny záznamy). Jinak použije standardní SQL podmínku pro zadanou hodnotu.
TIP: Před upravením stažené šablony doporučuji uložit původní/funkční šablonu. Může se stát, že šablonu neopravitelně poškodíte a bude pro Vás snažší začít znovu.
Šimeček